


Yellow.ai's Multi-Region Expansion - Charting the Course ( Part One )


In the ever-evolving landscape of conversational AI, Yellow.ai has emerged as a global leader, pioneering autonomous, human-like experiences to foster meaningful brand engagement. To further enhance our capabilities, we embarked on a journey towards enabling our platform in multiple regions. This blog delves into the motivations behind this strategic move, our multi-region architecture, the challenges we encountered, what goes into developing software in a multi-region multi-cloud platform, and how this impacts our business.
The Motivation Behind Multi-Region Deployments
We are committed to delivering exceptional conversational AI experiences worldwide. Multi-region deployment was a strategic imperative driven by several key factors:
Global Reach: To cater to a global customer base, we needed infrastructure closer to end-users, reducing latency, and improving response times
Scalability: Multi-region deployment allows us to efficiently scale our infrastructure to meet the growing demands of our global user base, ensuring that we can accommodate the individual needs of each region.
Data Privacy and Compliance: Compliance with diverse data privacy regulations necessitated data localization in specific regions
The Pledge: Preparing For Multi-Region
“Every great magic trick consists of three parts or acts. The first part is called "The Pledge". The magician shows you something ordinary: a deck of cards, a bird, or a man. He shows you this object. Perhaps he asks you to inspect it to see if it is indeed real, unaltered, normal. But of course... it probably isn't. ”
― Christopher Priest, The Prestige
Pre Multi-Region Days
Initially, the Yellow.ai platform was constructed primarily for a single region. As a result, all the microservices were structured around this mindset. Let’s take a look at the architecture of the system running in a single region.
The end users can communicate with us through the platform URLs or external channel sources. The traffic arrives at a public Load Balancer and then pours into our Load Balancer - HAProxy. HAProxy helps to route the traffic to different backend systems like Ejabberd (XMPP) and Kubernetes. From HAProxy, the traffic flows to Nginx, the entry point of the managed Kubernetes cluster. Nginx plays a pivotal role in routing requests to various Kubernetes-registered services, where each service is configured as a route within Nginx following the pattern "/api/service-name". These services connect to the databases running in a different subnet. The bots run in their own namespace and are segregated by their type. They can communicate with the customer’s systems through an egress controller that has a set of static IPs. This is particularly useful when customers want to allowlist IP addresses that can access their systems.

Replication of this architecture and its transformation into a multi-region compatible system posed its own set of challenges. The need to be cloud-agnostic was considered as popular cloud providers were not available in every region. This need also helped us avoid any vendor lock-ins. Even if a popular cloud provider existed in a region, the following points had to be taken into consideration.
Complexity Management: Handling increased complexity in network configurations, data synchronization, and monitoring
Storage Mechanisms: Using a cloud-agnostic object-storage interface
Cost Optimization: Selecting the ideal zone in a region with reliability and cost-effectiveness
External Channel Webhooks: Handling messaging channels that do not support conditional webhooks for region-based routing of messages to our platform
Picking New Cloud Regions
We had to pick new cloud regions and ensure they were the right place to serve our target markets. Based on this, we had to evaluate the different regions on their uptime, cost, service availability, proximity to customers, and cloud provider support. In India, we already had our services set up in Mumbai. After carefully evaluating the different options, we decided to go with the following regions as they aligned as closely as possible to the metrics.

The Turn: Adopting Cloud-Agnostic Multi-Region Strategies
“The second act is called "The Turn". The magician takes the ordinary something and makes it do something extraordinary. Now you're looking for the secret... but you won't find it, because of course you're not really looking. You don't really want to know. You want to be fooled.”
― Christopher Priest, The Prestige
However, in our case, we were transforming an already extraordinary platform into a new beast altogether. There were several architectural changes required before we could see different regions seamlessly communicate among themselves and with the end users. Let’s go through how we solved these challenges.
The Basics: Cluster Replication
We had to replicate the Kubernetes cluster over to the new regions which included creating the cluster, spinning up virtual machines for the databases, adding nodes to the cluster, and configuring subnets. You know how it goes. Once the whole cluster was ready, we moved on to the next problem.
Cluster Reachability
Up next, we ensured that the regions were reachable through the Internet. The platform’s front end runs in the primary cluster. Depending on the chatbot selected, the front end would call region-specific URLs that were resolved to a Cloudflare LoadBalancer. Based on the host, Cloudflare would forward the request to the appropriate public LoadBalancer. This solution could be extended to any number of clusters without a problem.

Since Cloudflare offered Multi-Domain Certificates, it made it easier for us to use the same certificate for all our domains. We added all our domains as Subject Alternative Names to the same certificate and reduced the time required to configure certificates for all the regions. For the enthusiasts out there, you can examine the certificate we load on our platform to see this in action.
Each of the regions was assigned a unique region code. Appending these codes to the base domain results in the calls reaching the region-specific Kubernetes cluster. For example, the URL https://z0.cloud.yellow.ai reaches the India cluster while the URL https://z4.cloud.yellow.ai reaches the USA cluster.
z0 - India
z1 - Bahrain
z2 - Jakarta
z3 - Singapore
z4 - USA
z5 - Europe
Extend the Authentication System
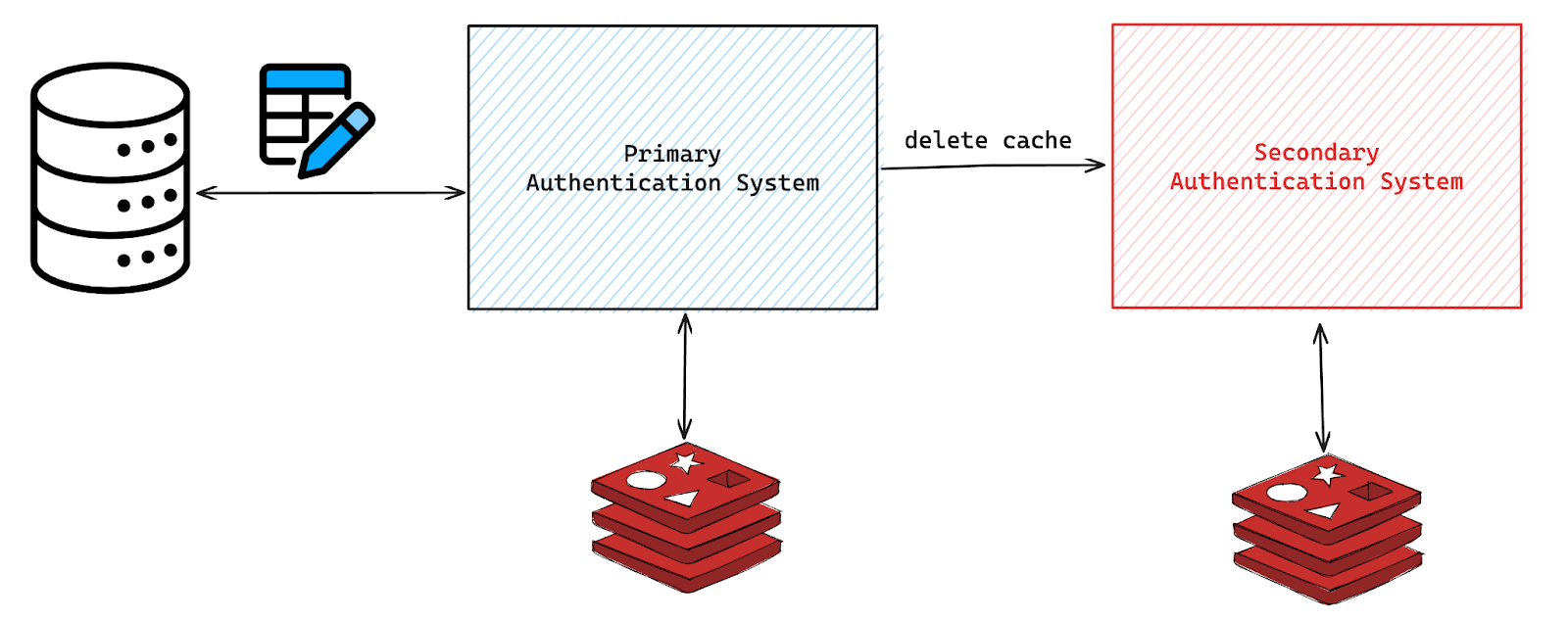
The decision to extend our authentication system stemmed from a fundamental challenge: the primary system’s access to a critical MySQL database containing essential chatbot metadata such as names and regions, the user account data, and the user roles. This metadata was indispensable for deploying the Yellow.ai platform globally. While replicating the entire database across regions wasn't an immediate option, we found a viable solution by extending our application's capabilities.
To put it into context, here's the issue: the primary authentication system in India possessed the sole access to the MySQL database housing the bot metadata. This data forms the bedrock of our bot deployment process worldwide, enabling us to load bots across the globe seamlessly. So, let's dive into the challenges and the ingenious solution that allowed us to seamlessly make our platform a global system.
We added support in the authentication system to become region-aware and categorized the system into primary and secondary. The primary would handle all incoming requests by itself and the secondary system would proxy incoming requests to the primary. To keep it simple, if the system was running in India, it operated as the primary, and if not, it operated as the secondary. Initially, this approach worked well. However, we soon realized that the latency of communicating from the West Coast of the United States to India was significantly slower than we expected. To address this, we introduced an allowlist that allowed the secondaries to handle specific APIs with a simple framework.
The logic behind this framework in the secondaries was straightforward:
Query Local Cache Layer for Authentication Data
Return if Cache is present
Else, query primary for the data, cache, and respond

There are only two hard things in Computer Science: cache invalidation and naming things.
― Phil Karlton
With this logic in place, we needed a robust cache invalidation mechanism to ensure that whenever data in the metadata database was updated, regions not directly connected to this database would invalidate their cache. To achieve this, whenever the primary system updated the metadata, the secondaries received a call from the primary to delete their cache. To prevent issues related to stale cache in case of any invalidation failure, we populated the cache in the secondaries with a short TTL.
Data Compliance
We had to be careful with data compliance because of strict regulations, as well as the belief system that made us do everything to protect our customers' data. We built the data flow in a way that the metadata about the customers goes to the India cluster, and the actual data of the customers resides in the databases in the region where their bot is configured to run. We ensured that no data, even accidentally, flowed outside the customer's region.
Callback Proxy for External Channels
In our journey towards multi-region deployment, we faced a challenge: the immutability of URLs for external channels. We had to work around the limitation of some external channels that could be configured to send data to only a single URL. To address this, we introduced the Callback Proxy. This solution utilizes a proxy server that acts as an intermediary between external channels and our multi-region architecture. When data arrives, the callback proxy's routing logic consults a metadata server to determine the appropriate destination, allowing seamless communication without altering existing channel configurations.
Cloud-Agnostic Object Storage
Next up, we confronted the task of integrating disparate storage systems inherent to each cloud provider. These unique storage offerings and protocols posed a significant obstacle to seamless interoperability. Our solution emerged in the form of MinIO, an open-source object storage server. MinIO adeptly bridged these divides, allowing us to harmonize our storage infrastructure, ensuring compatibility and data portability across multiple cloud environments. Since MinIO offers support for the s3 protocol out of the box, the applications do not have to worry about where the data is coming from, and they connect to the server in every deployment in the same way. This strategic adoption empowered us to harness the strengths of each cloud provider while preserving our vendor-agnostic approach.
Content Delivery Network ( CDN ) and Caching
We went ahead with Cloudflare to cache most of the frontend assets. This ensured the fast loading of assets despite the user’s location. We also tweaked the build pipelines to purge this cache whenever we built a new version of our frontend app or the chat widget.
The Prestige: Multi-Region Goes Live
“But you wouldn't clap yet. Because making something disappear isn't enough; you have to bring it back. That's why every magic trick has a third act, the hardest part, the part we call "The Prestige".”
― Christopher Priest, The Prestige
With these points being taken care of and through rigorous manual and automated testing, we released this multi-region capability to production. We patted ourselves on the back and rejoiced at this occasion.

However, we understood the importance of not resting on our laurels. This marked the initial phase, and as we know, challenges evolve.
Epilogue: Life with a Multi-Region Multi-Cloud Platform
Navigating life with such a complex platform requires vigilance and several considerations in the way we program the application, the way we roll out new changes and the way we scale it.
Programming Patterns
When working with microservices that interact with the metadata database, we have to be careful to not work with a single-region mindset. We should factor in the system design, the different regions available, and the fact that the same code can run in either a primary or secondary region, ergo, the same code can either have access to the metadata database or not.
Deployment Strategies
The deployment strategy should be decided during the time of initial system design to avoid hiccups during the rollout. We can achieve selective rollout for each region through feature gating, a glorified IF condition at the heart of the code. Essentially, the logic boils down to something like
IF ( isGateEnabled ) {
executeNewCode();
} ELSE {
continueWithOldCode();
}While feature gating is a valuable technique, we recognize the need for specialized strategies. Applying techniques like gating may not be universally suitable, particularly when dealing with database schema changes. To proactively address this, we emphasize the importance of considering rollout strategies during the initial design phase. This foresight helps mitigate deployment challenges. Additionally, we strongly discourage the use of different images for the same microservice across regions. This uniformity enables us to swiftly address any region-specific code incompatibilities and execute temporary rollbacks when necessary.
Scaling and Cost Management
Thanks to our amazing Infrastructure Engineering team, we’re able to understand the optimal configuration for each microservice running in each region with the help of instrumentation and the limits assigned to the Kubernetes workloads. With this, we adjust the workloads to the appropriate resource limits. HPA is set for each microservice by analyzing past traffic, and load testing the application to determine appropriate thresholds. This setup gives us the flexibility to individually scale each region depending on the anticipated traffic or gradual increase in consumption.
Final Notes
Yellow.ai's journey into multi-region deployment represents a pivotal step in our commitment to delivering exceptional conversational AI experiences globally. By understanding the challenges, and implementing a resilient architecture, we have fortified our position as a leader in the industry. This strategic move not only benefits our customers but also sets the stage for continued innovation and growth in the world of conversational AI.
This blog is the first part of a two-part series on multi-region deployments from Yellow.ai. In our next article, we'll delve into a critical issue: Eliminating Single Points of Failure.